|
12/8/2015 0 Comments Reinforcement LearningThis is the simulation interface that I recently developed to understand the working on Multi-armed bandit algorithm. There are many solutions to the problem. I simulated two solutions: multiplicative (multiply the winning experiment with alpha) and Thompson Sampling (which uses beta distribution to simulate and find optimal weights). In this post I will be showing a snapshot of simulation results after cutting down on the rest of the page content because of privacy issues. Algorithm is designed in a way that it can run in real time while exploring and exploiting various types of ad. It is also highly scalable as it runs on more than 5 million pages at any time. For simulation purposes I assumed Poisson behavior of arrival on a page and underlying phenomenon of video being served and user's reaction to it. Users favor higher number of format which is why 4 should win. 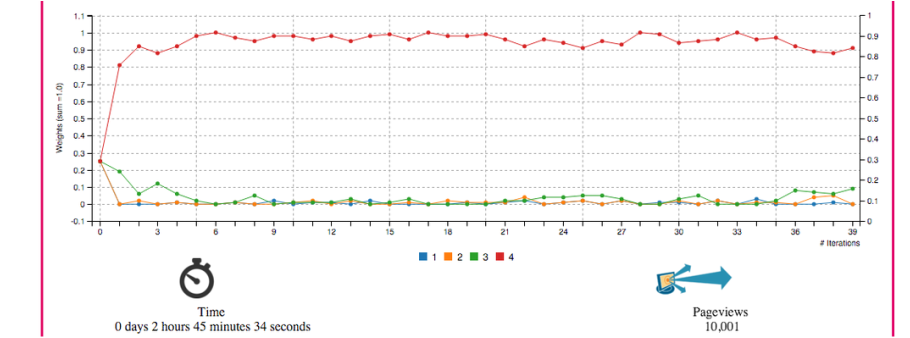 Above figure shows the simulation of internet traffic being treated with 4 different formats of browsing experience. Updating of weights is done using Thompson sampling method. Probability of success is simulated using beta distribution 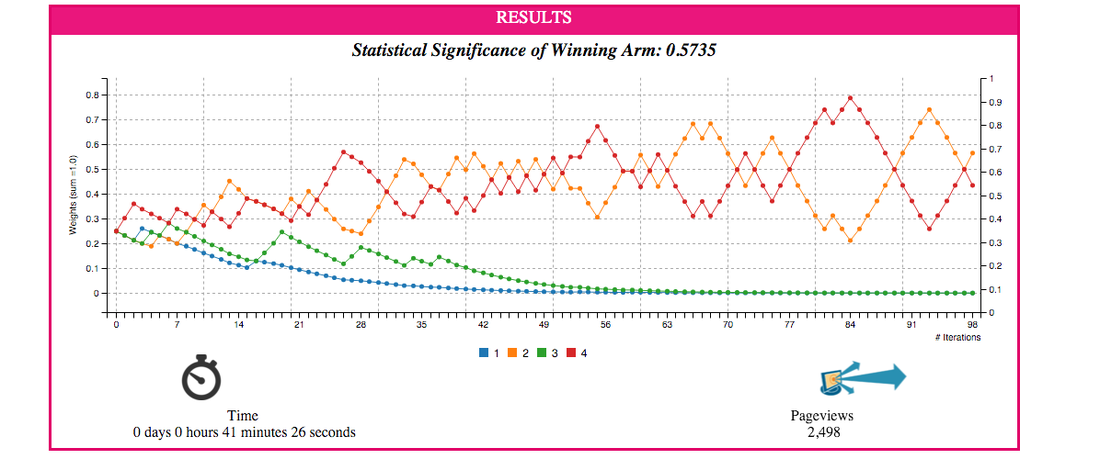 Above is the result of multiplicative solution. You reward the winning strategy and penalize the loosing ones. Exploitation is done by resetting the weights to initial weights.
0 Comments
Leave a Reply. |
